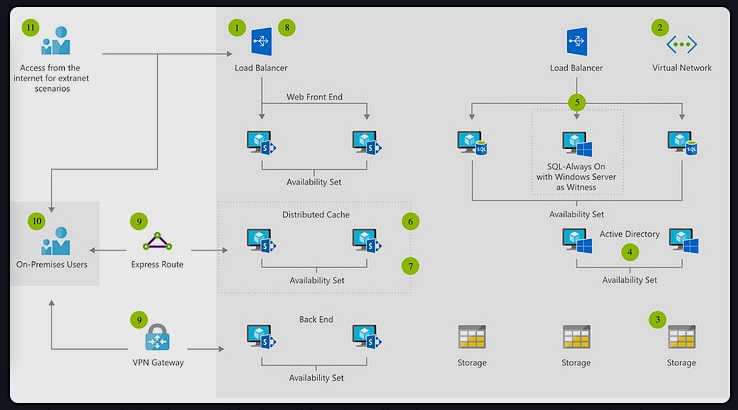
Nach erfolgter Dublettensuche zeigt das Programm die Dubletten gruppiert an.
Hier wollen Sie
- die Dubletten manuell durchsehen um das Ergebnis zu überprüfen
- bei dieser Durchsicht die Zuordnung für einzelne Sätze aufheben, bei denen es sich nicht um Dubletten handelt
- von den gefundenen Dubletten jeweils alle Sätze bis auf einen automatisch löschen.
Manuelle Durchsicht der Dubletten
Wenn Sie Dubletten in wichtigen Kundendatenbanken ö.ä. suchen, empfiehlt sich eine nachträgliche manuelle Durchsicht des Ergebnisses. Sie würden hierbei die Suche mit einem etwas niedrigerem Schwellenwert durchführen (80-85%), sodass eher zu viele Dubletten gefunden werden. In der manuellen Durchsicht heben Sie dann die Zuordnung zwischen angezeigten Dubletten auf, bei denen es sich nicht um eine Dublette handelt (s.u.). (Sie werden feststellen, dass es bei einzelnen Sätzen auch für den Menschen schwer zu entscheiden ist, ob es sich um eine Dublette handelt oder nicht). Durch die übersichtliche Darstellung der Dubletten ist eine manuelle Durchsicht in relativ kurzer Zeit möglich und lohnt den Aufwand.
Bei Marketingadressen o.ä. Daten, bei denen es nicht viel ausmacht, wenn einige Sätze wegfallen, können Sie evtl. auf die manuelle Durchsicht verzichten. Sie würden hierbei einen etwas höheren Schwellenwert (90-95%) bei der Dublettensuche wählen, sodass nur sichere Dubletten gefunden werden. Diese können Sie dann ohne grosses Risiko automatisch bereinigen (d.h. automatisch Sätze in einem Dublettenpaar löschen, s.u.)
Zuordnung für einzelne Sätze aufheben
Um eine Dubletten-Zuordnung zwischen zwei Sätzen aufzuheben (zu sagen: dies ist keine Dublette) markieren Sie einen Satz und wählen "Durchsicht->Zuordnung aufheben".
TIPP: Diese Aktion erreichen Sie auch durch Rechtsklick mit der Maus auf einen Datensatz.
Löschliste erstellen
Nach der manuellen Durchsicht und Entfernung von ungültigen Dubletten wollen Sie alle Datensätze in Dubletten löschen, sodass je Dublette nur ein Datensatz erhalten bleibt (alle ähnlichen gelöscht werden). Nach diesem Löschvorgang ist Ihre Datenbank frei von Dubletten.
Wählen Sie dazu Menü Dubletten->Löschliste erstellen, um eine Liste der zu löschenden Sätze zuerstellen.

Um den ältesten/jüngsten Satz zu erhalten, teilen Sie dem Programm eine entsprechende Spalte für die Sortierreihenfolge mit. Wählen Sie z.B. eine Spalte created o.ä., sofern Ihre Datenbank eine Spalte mit Erstellungsdaten zu jedem Datensatz enthält. Auch die Autonumber-Spalte in Access und SQL-Server Datenbanken enthält grundsätzlich Werte in chronologisch aufsteigender Reihenfolge und kann zu diesem Zweck verwendet werden.
Dubletten löschen
Nach Erstellung der Löschliste wählen Sie Menü Dubletten->Dubletten löschen, um diese Datensätze aus Ihrer Datenbank zu löschen oder eine temporäre Tabelle Ihrer bereinigten Daten anzuzeigen.
Bitte prüfen Sie vorher, ob das Löschen in Ihrer Tabelle überhaupt zulässig ist. Dies könnte z.B. nicht der Fall sein, wenn diese Tabelle mit anderen Tabellen in Ihrer Datenbank verknüpft ist. Berücksichtigen Sie auch, dass durch Verknüpfungen mit anderen Tabellen durch das Löschen u.U. auch andere Daten gelöscht werden könnten.
Überprüfen Sie also das Datenmodell oder klären Sie mit dem Entwickler der Datenbank, ob Sie ohne Weiteres Datensätze aus dieser Tabelle einfach löschen dürfen.
Das Erstellen einer bereinigten Tabelle ist dagegen gefahrlos möglich und verändert nicht Ihre Datenbank.